- Docs
- /
SQL SERVER BACKUP
17 Apr 2021 16450 views 0 minutes to read Contributors ![]()
BACKUPS IN SQL SERVER
INTRODUCTION
A relational database is simply a set of files that store data. When we make backups of these files, we capture the objects and data within those files and store them in a backup file. So, database backup is just a copy of the database as it existed at the time the backup was taken.
Backups Strategies are used to recover the data or minimize the risk of data loss in case a failure happens.
Importance of Backups
There are a variety of failures that can occur at various stages of the life of the solution. Though we can take some proactive measures to ensure failures are minimized, it’s not guaranteed that it will not happen. However, we can set up proper backup and restore strategies to ensure that if any failure happens, we have a mechanism in place it recovers from it.
There are several types of failure that we often encounter:
- Hardware failure (SQL Server instance failure, Network failure, Media and Disk failure) – Although with the latest hardware in the market and with inbuilt redundancy and failover capabilities, the chances of failure are greatly reduced, it still can happen. For example, the controller on the disk might fail to work, data on the disk might get corrupted etc.
- System and Software failure – This is related to the failure of the operating system, or CPU or main memory of a computer system. System and Software failure may be caused by a power failure, an application or operating system crash, memory error or some other reason.
- Application failure – This kind of failure might happen because of some bugs in an application, which modified (inserted\updated\deleted) data unwantedly. For example, consider updating the salary for an employee without having a WHERE clause. Another example could be related to logic, for example, the salary for an employee was supposed to be incremented by 20% but it actually got incremented by 200%.
- User failure – User failure is similar to application failure with the exception that here data gets modified (inserted\updated\deleted) unwantedly by a user. For example, a user wanted to delete one specific row from a table but executed the DELETE statement without the WHERE clause.
Backups Type
The database backup, which is a backup of your primary data file plus any secondary database files, is the cornerstone of any enterprise's backup and recovery plan. Generally, there are Different type of backups in sql and usage depends on the requirement of the customer.
1) Full Backups
2) Differential Backups
3) Transaction Log Backups
4) Tail Log Backup
5) File and Filegroup Backup
6) Partial Backup
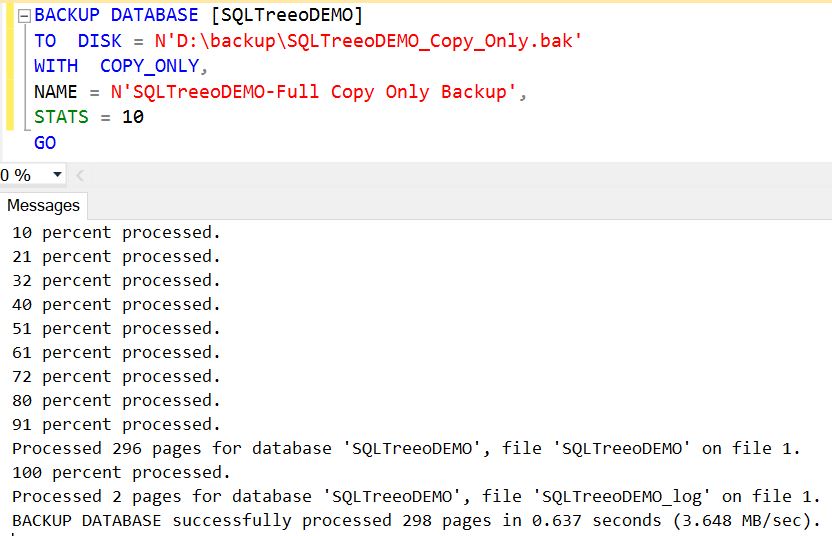
7) Copy Only Backup
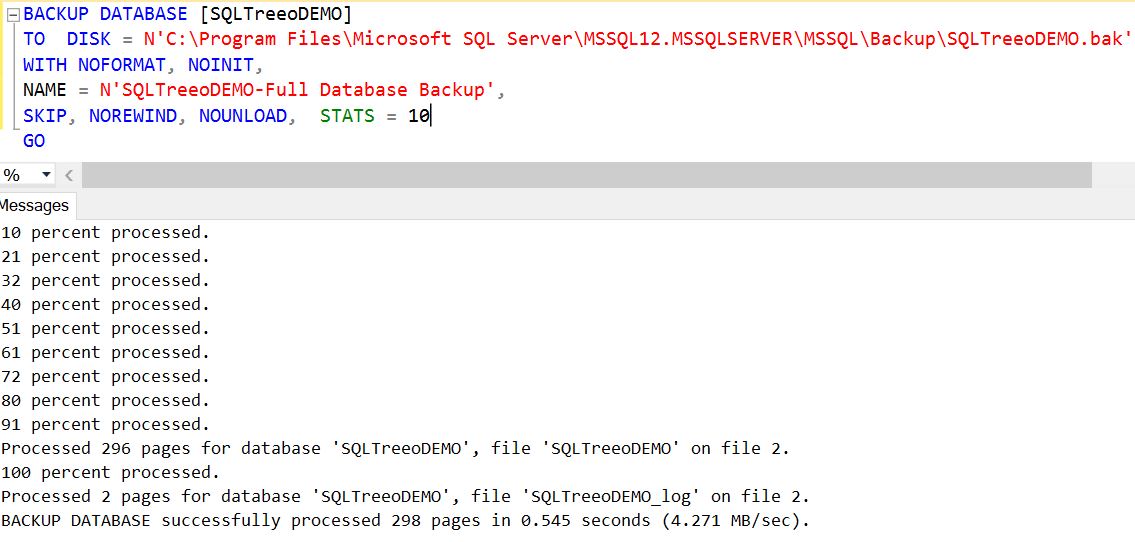
Full Backup
A full database backup will contain every detail of your database: tables, stored procedures, functions, views, permission information, indexes and, of course, the data stored within those tables.
It will also contain just enough information from the transaction log to guarantee that the database can be restored to a consistent state (for example, it needs to back up enough of the log to be able to roll back any transactions that started before the backup and had not committed by backup completion), and to get the database back online in the case of failure during a restore operation.
Differential Backup
The differential backup is very similar to the full backup, in that it contains a record of the objects and data contained within the data file or files, but the differential backup file will contain only the data that has been changed since the last full backup was taken. This means that a full database backup must be taken before a differential database backup can be performed, otherwise the system will not have a way of knowing what data has been modified. This full backup is known as the base of the differential.
Differential Changed Map (DCM) is a bitmap page that contains a bit for every extent and tracks the extents that have changed since the last full database backup. When you take full database backup, the bit for each extent is reset to 0 and then if there is any change in the extent after that, the bit is changed to 1. During differential backup, SQL Server identifies all the extents for which the bit value is 1 by looking at these DCM pages and hence the length of time that a differential database backup runs is proportional to the number of extents modified (value set to 1) since the last full database backup and not the overall size of the database.
Differential backups are cumulative in nature, which means if you take a full database backup on Sunday followed by differential backups on Monday, Tuesday and Wednesday, and if you want to restore till Wednesday, then you must restore your latest full database backup first followed by restoring the most recent differential backup (example differential database backup taken on Wednesday) only.
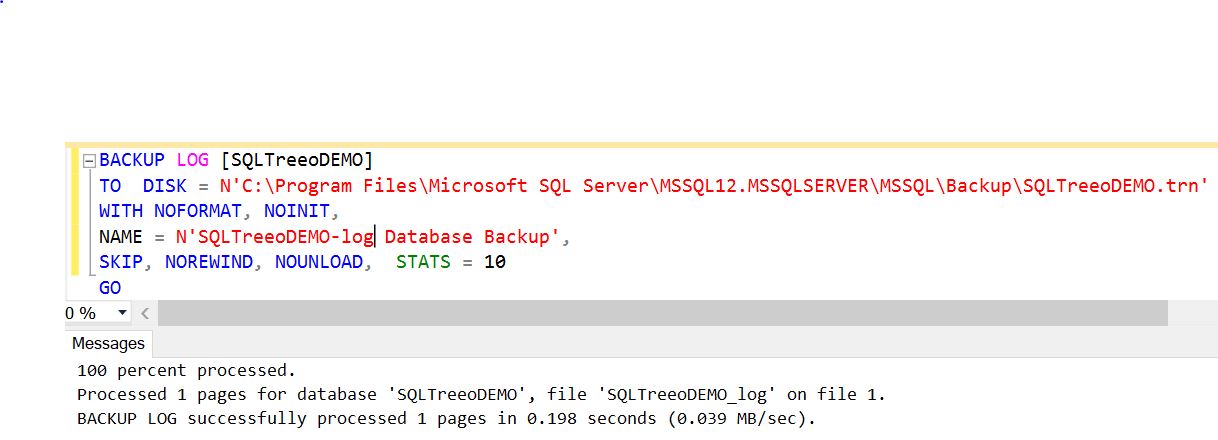
Transactional Log Backup
Transaction log backup is supported only with either Full recovery model or Bulk-logged recovery model and like differential database backup, you must have taken a full database backup as its base. Transaction log backup captures all the transaction log records that have been written after the last full database backup or last transaction log backup.
It’s recommended to take transaction log backups frequently enough to minimize the data loss exposure and to truncate the transaction log so that it does not grow significantly long. Please note, transaction log does not get truncated (even after checkpoint operation) for committed transactions unless you take the transaction log backup. There are certain other cases as well when transaction log will not get truncated, for example if you have setup Always On, Database mirroring, Transactional replication, Log shipping, Change Data Capture and they are not working correctly. This will cause a delay to the transaction log truncation.
Unlike differential database backup, which captures only the last changed values when a row was changed repetitively, transaction log backup captures all the changes with each repetition.
Tail Log Backup
In the event of a failure affecting a database operating in FULL or BULK_LOGGED recovery model, the first action after the failure should be to perform what is known as a tail log backup of the live transaction log, which captures the remaining contents of this file. In fact, a subsequent RESTORE operation may otherwise fail, unless the command includes WITH REPLACE, indicating that the existing database should be overwritten, or WITH STOPAT, indicating that there is a specific point at which we wish to stop the restore operation.
If a database is corrupted in some way, but is still online and we wish to restore over that database, then performing a tail log backup with BACKUP LOG…WITH NORECOVERY, will capture the remaining contents of the live log file and put the database into a restoring state, so that no further transactions against that database will succeed, and we can begin the restore operation.
This sort of tail log backup, as well as normal log backups, require the database to be online (I believe, so that information regarding the log backup can be stamped into the database header). If the database is offline, and an attempt to bring it back online fails, perhaps because a data file is unavailable, then a tail log backup WITH NORECOVERY, as well as any normal log backups, will fail. However, it may still be possible to perform a tail log backup, but using the NO_TRUNCATE option instead, BACKUP LOG…WITH NO_ TRUNCATE. This operation backs up the log file without truncating it and doesn't require the database to be online.
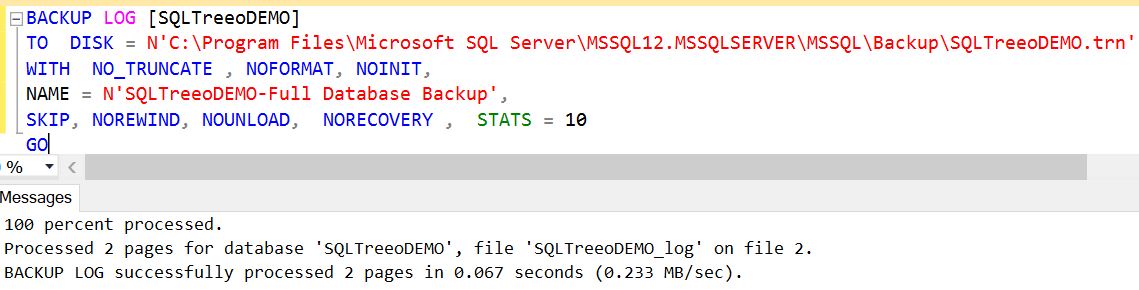
there is a special case where a tail log backup may not succeed, and that is if there are any minimally logged transactions, recorded while a database was operating in BULK_LOGGED recovery model, in the live transaction log, and a data file is unavailableas a result of the disaster. A tail log backup using NO_TRUNCATE may "succeed" (although with reported errors) in these circumstances but a subsequent attempt to restore that tail log backup will fail.
File and Filegroup Backups
Sometimes when the size of your database grows significantly, it becomes difficult to take a full database backup; when that happens, you can consider taking a file or filegroup backup, which change frequently (some files or file groups will have static data or will be read-only and hence it would not be required to frequently take a backup of these files or file groups). This is the copy of the files or file groups of the database.
For a larger database, there might be several files or file groups; some might change frequently and some rarely (example a file or file group containing archived data). In this case you can setup a process to backup the frequently changing file or filegroup. You can choose to backup and restore each individual file or can choose the whole filegroup instead of specifying each constituent file individually. This greatly increases the speed of recovery by letting you restore only damaged files, without worrying about restoring the rest of the database.
File or File group backup and restore comes with additional administrative complexity example maintaining and keeping track of a complete set of these backups can be a time-consuming task that might outweigh the space needed and time required for a full database backup. Also, a table and all of the indexes must be backed up in the same backup and hence if you intend to use file or file group backup you need to plan placing a table and all its indexes on the same file/filegroup.
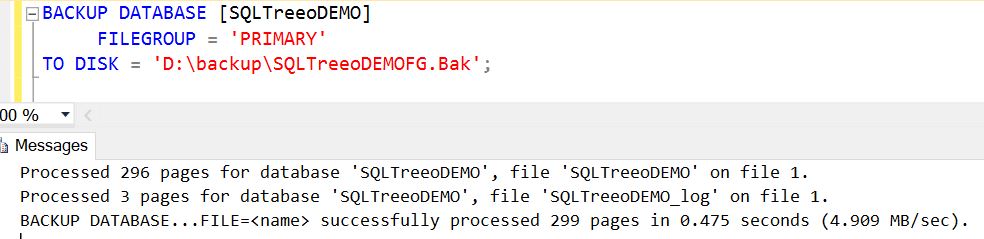
Partial Backup
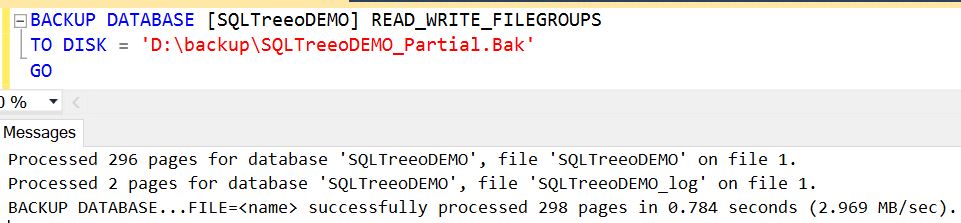
If you have a very large database with a couple of file groups and only a few of them are changing, you can reduce the time to take the backup by backing up only those parts of the database which are changing. A partial backup is similar to a full database backup but takes a backup of only the primary filegroup and every read-write file group (optionally you can include one or more read-only file groups as well). If you take a partial backup of a read-only database it only contains the primary filegroup. Partial backup might be helpful if you want to exclude read-only file groups to reduce overall backup time.
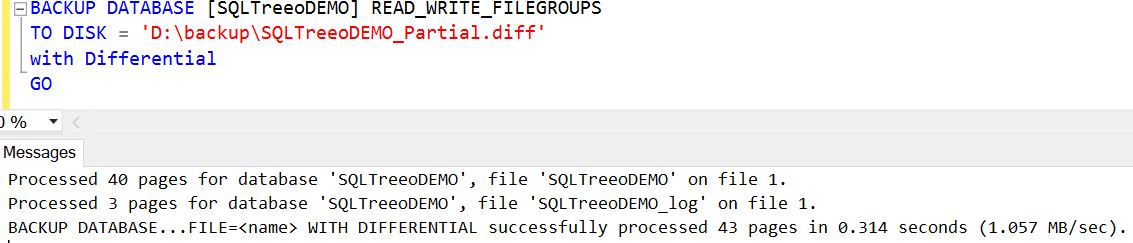
Like differential backup works with full backup, you can take a differential partial backup based on a partial backup as base. As in the case of differential backup, differential partial backup captures all the extent modified since the last partial backup.
With partial backups, we only need to take transaction log backups if they are needed for point-in-time recovery, and so they are ideal for use with SIMPLE recovery model databases, as a means to trim database backups down to a more manageable size, without introducing the added administrative overhead of log backups. Note that partial backups are valid for databases operating in any recovery model; it's just that they were specifically designed to simplify back up for very large, SIMPLE recovery model databases that contain a large portion of read-only data.
Create a SQL Server full partial backup
Create a SQL Server differential partial backup
COPY_ONLY Backup
Copy-Only backup, as its name implies, takes the copy of the database without changing the normal sequence of conventional backup operation. Copy-Only backup can be done at the database level or transaction log level.
As said before, when you take a full database backup, SQL Server resets bits to 0 for all the extents in the DCM page, likewise with transaction log backup, it resets how the next transaction log backup should happen but when you take Copy-Only full backup, it does not interfere with normal backup\restore operations and does not reset bits to 0 for all the extents in DCM page at the same time; when you take Copy-only transaction log backup, it preserves the existing log archive point and the transaction log is never truncated after a Copy-Only log backup.
Copy-Only database backup and restore might be helpful if you want to setup development\testing\QA environment without impacting the regular backup and restore rhythm setup in production.