
- Docs
- /
COLUMNSTORE INDEX IN SQL SERVER
28 Mar 2021 47215 views 0 minutes to read Contributors ![]()
COLUMNSTORE INDEX IN SQL SERVER
INTRODUCTION
Columnstore indexes were first introduced in SQL Server 2012. They are a new way to store the data from a table that improves the performance of certain query types by at least ten times. They are especially helpful with fact tables in data warehouses.
When columnstore indexes were first introducedyou couldn’t update a table with a columnstore index without removing it first. Fortunately, there have been many improvements since then.These indexes are very useful for data warehouse workloads and large tables. They can improve query performance by a factor of 10 in some cases, so knowing and understanding how they work is essential if you work in an environment with larger scaled data. They are worth taking the time to learn.
Architecture of Columnstore Indexes
First, we need to understand some terminology and the difference between a columnstore index and a row store index (the typical kind we all use).
Columnstore simply means a new way to store the data in the index. Instead of the normal Rowstoreor b-tree indexes where the data is logically and physically organized and stored as a table with rows and columns, the data in columnstore indexes are physically stored in columns and logically organized in rows and columns.
Instead of storing an entire row or rows in a page, one column from many rows is stored in that page. It is this difference in architecture that gives the columnstore index a very high level of compression along with reducing the storage footprint and providing massive improvements in read performance.
The index works by slicing the data into compressible segments. It takes a group of rows, a minimum of 102,400 rows with a max of about 1 million rows, called a rowgroup and then changes that group of rows into Column segments. It’s these segments that are the basic unit of storage for a columnstore index.
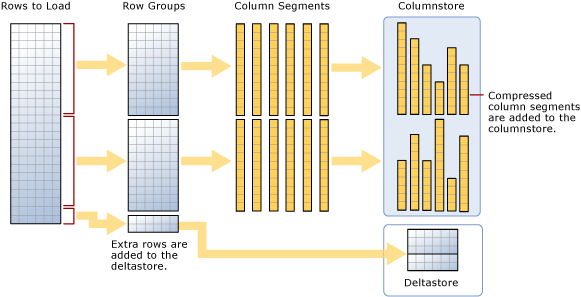
Imagine this is a table with 2.1 million rows and six columns. Which means that there are now two rowgroups of 1,048,576 rows each and a remainder of 2848 rows, which is called a deltagroup. Since each rowgroup holds a minimum of 102,400 rows, the delta rowgroup is used to store all index records remaining until it has enough rows to create another rowgroup. You can have multiple delta rowgroups awaiting being moved to the columnstore. Multiple delta groups are stored in the delta store, and it is actually a B-tree index used in addition to the columnstore. Ideally, your index will have rowgroups containing close to 1 million rows as possible to reduce the overhead of scanning operations.
Now to complicate things just one step further, there is a process that runs to move delta rowgroups from the delta store to the columnstore index called a tuple-mover process. This process checks for closed groups, meaning a group that has a maximum of 1 million records and is ready to be compressed and added to the index. As illustrated in the picture, the columnstore index now has two rowgroups that it will then divide into column segments for every column in a table. This creates six pillars of 1 million rows per rowgroup for a total of 12 column segments. It is these column segments that are compressed individually for storage on disk. The engine takes these pillars and uses them for very highly paralleled scans of the data. You can also force the tuple-mover process by doing a reorg on your columnstore index.
To facilitate faster data access, only the Min and Max values for the row group are stored on the page header. In addition, query processing, as it relates to column store, uses Batchmode allowing the engine to process multiple rows at one time. This also makes the engine able to process rows extremely fast in some cases, giving two to four times the performance of a single query process. For example, if you are doing an aggregation, these happen very quickly as only the row being aggregated is read into memory and using the row groups the engine can batch process the groups of 1 million rows. In SQL Server 2019, batch mode is also going to be introduced to some row store indexes and execution plans.
Another interesting difference between columnstore indexes and b-tree indexes is that columnstore indexes do not have keys. You can also add all the columns found in the table, as long as they are not a restricted data type, to a non-clustered columnstore index, and there is no concept of included columns. This is a radically new way of thinking if you are used to tuning traditional indexes.
Benefits from the Columnstore index.
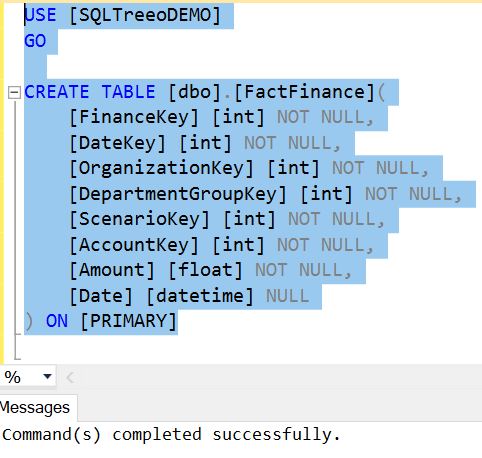
We will start with creating the FactFinance table in our SQLTreeoDemo test database with the T-SQL script below
Once the table is created then we will create a clustered index on that table.

Now the table is ready. If we run the below simple SELECT statement on the created table and check its execution plan generated.

The execution Plan is as follows:

Now we will create the ColumnStore Non-Clustered index simply using the normal CREATE NONCLUSTERED INDEX statement with specifying the COLUMNSTORE keyword:

If we execute the same SELECT statement below and check execution plan.

The ColumnStore Index scan operator will be shown here. Nothing till now tell us that there is any enhancement. Let’s again go deeply with that operator to check the same parameters taken before as follows:

CLUSTERED INDEX SCAN OPERATOR COST ANALYSIS
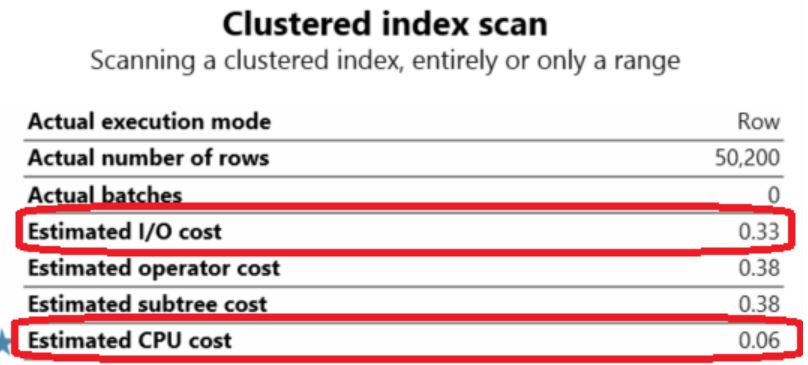
Estimated I/O Cost which equals to 0.33 and the Estimated CPU Cost which equals to 0.06
COLUMNSTORE INDEX SCAN OPERATOR COST ANALYSIS

As you can see, the Estimated I/O Cost decreased clearly from 0.33 when using the row-store standard index to 0.07 in the Columnstore index case. This is because the SQL engine retrieves only the requested columns from the table without wasting I/O and Memory resources to retrieve the data.
The Estimated CPU time still the same, as the query is retrieving small amount of data and no batch execution required here.
ANALYSING LOGICAL READS FROM BOTH THE SCENARIOS
You can find the same result when comparing the number of logical reads performed by each query. It is clear also that the number of reads using the standard Clustered index is 4 times the number of reads using the Columnstore index.

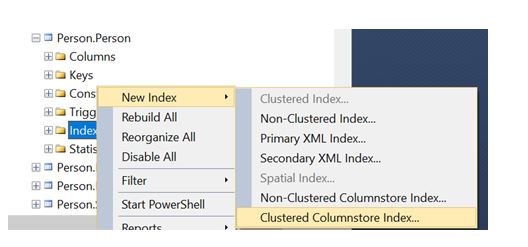
You can also create the Columnstore index using SQL Server Management Studio by expanding the table in the object explorer and right-click on the Indexes -> New Index ->Non-Clustered Columnstore Index as below:
IMPORTANT POINTS TO REMEMBER
- If we try to create a Clustered Columnstore index in our table, it will fail as we already have other indexes on that table, and as we mentioned previously, the Clustered Columnstore index can’t be combined with other indexes in the same table
- Assume that you don’t have any index in your table, you will be able to create the Clustered Columnstore index successfully, without having the option to choose the included columns, as all the columns will be included in that index, which will be the main data store for that table: